TensorFlow Scala - Linear Regression via ANN
![]()
TensorFlow Scala is a strongly-typed Scala API for TensorFlow core C++ library developed by Anthony Platanios. This library integrates with native TensorFlow library via JNI, so no intermediate official/non-official Java libraries are used.
In this article we will implement "multiple linear regression" from the previous article about Customer Churn using TensorFlow.
Setup Project
I am going to use SBT, but you can also use any other Scala-aware build tool.
New SBT project configuration:
lazy val tensorFlowScalaVer = "0.5.10"
lazy val root = (project in file("."))
.settings(
name := "tensorflow-scala-example",
libraryDependencies ++= Seq(
"org.platanios" %% "tensorflow-data" % tensorFlowScalaVer,
"org.platanios" %% "tensorflow" % tensorFlowScalaVer classifier "darwin"
)
)In order to add TensorFlow Scala to existing project, just add two library dependencies from above configuration. tensorflow-data module is optional, but we are going to use it
in this article as well.
Important: I am using OSX, so my classifier is darwin. In case you use Linux or Windows, please change classifier value to currently available classifiers for those platforms, check it here to be sure: https://repo1.maven.org/maven2/org/platanios/tensorflow_2.13/0.5.10/.
Tensor API
Before start implementing an Artificial Neural Network with TensorFlow, let's briefly look at how we can load data into a tensor.
We would need to create matrices, so we can use Scala collections and map Arrays to Tensors and put them as rows into another Tensor. For example:
import org.platanios.tensorflow.api._
val t1 = Tensor(Tensor(1, 4, 0), Tensor(2, 3, 5))
println(t1.summarize())will print:
Tensor[Int, [2, 3]]
[[1, 4, 0],
[2, 3, 5]]Data Preparation
TensorFlow Scala also has data API to load datasets. We will use that API
partly. Unfortunately, current documentation does not give an idea how to use Data API, so that we will use partly. Most of data preparation code I took from previous article.
Custom Code
type Matrix[T] = Array[Array[T]]
private def createEncoders[T: Numeric: ClassTag](data: Matrix[String])
: Matrix[String] => Matrix[T] = {
val encoder = LabelEncoder.fit[String](TextLoader.column(data, 2))
val hotEncoder = OneHotEncoder.fit[String, T](TextLoader.column(data, 1))
val label = t => encoder.transform(t, 2)
val hot = t => hotEncoder.transform(t, 1)
val typeTransform = (t: Matrix[String]) => transform[T](t)
label andThen hot andThen typeTransform
}
def loadData() = {
// loading data from CSV file into memory
val loader = TextLoader(Path.of("data/Churn_Modelling.csv")).load()
val data = loader.cols[String](3, -1)
val encoders = createEncoders[Float](data)
val numericData = encoders(data)
val scaler = StandardScaler[Float]().fit(numericData)
// create data transformation as custom code
val prepareData = (t: Matrix[String]) => {
val numericData = encoders(t)
scaler.transform(numericData)
}
// transform features
val xMatrix = prepareData(data)
val yVector = loader.col[Float](-1)
Tensor API
Continuation of loadData:
import org.platanios.tensorflow.data.utilities.UniformSplit
// Wrap arrays into Tensors and set Shapes
val xData = xMatrix.map(a => Tensor(a.toSeq)).toSeq
val x = Tensor(xData).reshape(Shape(-1, features))
val y = Tensor(yVector.toSeq).reshape(Shape(-1, targets))
// use library API to split data for train and test sets
val split = UniformSplit(x.shape(0), None)
val (trainIndices, testIndices) = split(trainPortion = 0.8f)
val xTrain = x.gather[Int](trainIndices, axis = 0)
val yTrain = y.gather[Int](trainIndices, axis = 0)
val xTest = x.gather[Int](testIndices, axis = 0)
val yTest = y.gather[Int](testIndices, axis = 0)
(xTrain, yTrain, xTest, yTest, prepareData)
}As per comments above, we prepare training and test data and return it as 4 different Tensor objects. Also, we return a function as fifth element of the tuple for one more application (read further).
Full code of data preparation that includes:
- selecting specific CSV file columns
- normalising numeric columns
- encoding categorical columns as one-hot
- encoding label-like columns
see here:
Model Assembly
We are going to learn on 12 features to predict one target.
val features = 12
val targets = 1
val batchSize = 100
val input = tf.learn.Input(FLOAT32, Shape(-1, features))
val trainInput = tf.learn.Input(FLOAT32, Shape(-1, targets))batchSize will be used in a couple of places of TensorFlow API.
In order to construct all 12 x 6 x 6 x 1 network below:
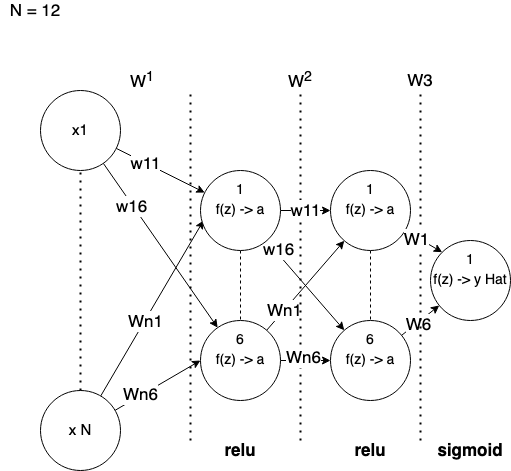
we use the following API:
val layer =
tf.learn.Linear[Float]("Layer_0/Linear", 6) >>
tf.learn.ReLU[Float]("Layer_0/ReLU") >>
tf.learn.Linear[Float]("Layer_1/Linear", 6) >>
tf.learn.ReLU[Float]("Layer_1/ReLU") >>
tf.learn.Linear[Float]("OutputLayer/Linear", 1) >>
tf.learn.Sigmoid[Float]("OutputLayer/Sigmoid")layer state is a composition of fully-connected layers with its own activation function. We specify String name for each layer that will be eventually used in TensorFlow graph.
val loss = tf.learn.L2Loss[Float, Float]("Loss/L2Loss")
val optimizer = tf.train.Adam()We are going to use L2, which is a half least square error as a loss function.
And Adaptive Moment Estimation (Adam) as weights optimization algorithm.
Finally, we pass above values to construct simple supervised model.
val model = tf.learn.Model.simpleSupervised(
input = input,
trainInput = trainInput,
layer = layer,
loss = loss,
optimizer = optimizer,
clipGradients = ClipGradientsByGlobalNorm(5.0f)
)You can also create unsupervised model with .unsupervised method, if needed.
As we can see, model construction is highly declarative as the entire TensorFlow Scala library API.
Estimator
Another abstraction in TensorFlow we are going to use is Estimator. It is used to train, predict, evaluate and export for serving the TensorFlow models. In some other libraries, an estimator is usually a model abstraction itself. Estimator provides nice separation from the input data and actual model to train.
Dataset
Before we construct an estimator we need to wrap the input data into a Dataset. As I mentioned before, the TensorFlow Scala provides a data package to
load some data formats in streaming way / lazily. This is recommended way to use this library that allows us to iterate over the data in streaming fashion, so the full dataset does not need to fit into memory. However, our current example dataset is quite small. so that we used custom code to load and transform the data before we start any learning. Now we have to wrap Tensors into Datasets:
val (xTrain, yTrain, xTest, yTest, dataTransformer) = loadData()
val trainFeatures = tf.data.datasetFromTensorSlices(xTrain)
val trainLabels = tf.data.datasetFromTensorSlices(yTrain)
val testFeatures = tf.data.datasetFromTensorSlices(xTest)
val testLabels = tf.data.datasetFromTensorSlices(yTest)
val trainData =
trainFeatures
.zip(trainLabels)
.repeat()
.shuffle(1000)
.batch(batchSize)
.prefetch(10)
val evalTrainData = trainFeatures.zip(trainLabels).batch(batchSize).prefetch(10)
val evalTestData = testFeatures.zip(testLabels).batch(batchSize).prefetch(10)Output
Above code creates training dataset as combination of features and labels outputs.
Core TensorFlow library has an idea of Output abstraction. The Output is a symbolic handle that represents a tensor value produced by an Operation. In other words, it is future state of a Tensor once particular operand is applied to that tensor. It does not hold the values of that operation
output, but instead provides a means of computing those values in a TensorFlow Session, which is another TensorFlow abstraction. The session is created automatically by the Estimator. One can also construct TensorFlow session manually, we are not going to do this in this article.
Training Metrics
One of the place where we work with Outputs directly in this example, is
training metric configuration. For binary classification we need to transform predicted
values by the model to 0 and 1.
val accMetric = tf.metrics.MapMetric(
(v: (Output[Float], (Output[Float], Output[Float]))) => {
val (predicted, (_, actual)) = v
val positives = predicted > 0.5f
val shape = Shape(batchSize, positives.shape(1))
val binary = tf
.select(
positives,
tf.fill(shape)(1f),
tf.fill(shape)(0f)
)
(binary, actual)
},
tf.metrics.Accuracy("Accuracy")
)I think to transform predicted values to binary values, i.e. 1 and 0 can be done more efficient than filling true boolean values with 1 and false values with 0 using tf.select function, but I could not find another way.
We will use above accuracy metric in estimator construction.
Construct Estimator
val summariesDir = Paths.get("temp/ann")
val estimator = tf.learn.InMemoryEstimator(
model,
tf.learn.Configuration(Some(summariesDir)),
tf.learn.StopCriteria(maxSteps = Some(100000)),
Set(
tf.learn.LossLogger(trigger = tf.learn.StepHookTrigger(100)),
tf.learn.Evaluator(
summaryDir = summariesDir,
log = true,
datasets = Seq(("Train", () => evalTrainData), ("Test", () => evalTestData)),
metrics = Seq(accMetric),
trigger = tf.learn.StepHookTrigger(1000),
name = "Evaluator"
),
tf.learn.StepRateLogger(
log = false,
summaryDir = summariesDir,
trigger = tf.learn.StepHookTrigger(100)
),
tf.learn.SummarySaver(summariesDir, tf.learn.StepHookTrigger(100)),
tf.learn.CheckpointSaver(summariesDir, tf.learn.StepHookTrigger(1000))
),
tensorBoardConfig =
tf.learn.TensorBoardConfig(summariesDir, reloadInterval = 1)
)Above code configures:
- Logging in training loop:
- log to summary directory "temp/ann"
- store checkpoint at every 1000 step to summary directory
- log at every 100 steps
- log loss value at every 100 steps
- Evaluate metrics:
- calculate accuracy metric (and any other specified metrics in Seq) at every 1000 step
- use data specified in Evaluator datasets
- Take data for Tensorboard from summary directory
- Stop after
100 000step unless overridden by.trainmethod
Note: estimator works with step notion rather than with epoch. In order to calculate number of desired training steps, you can divide a number training records on batch size. In our case we have 8000 training records / 100 batch size = 80 steps. This is one epoch, i.e. one full training cycle on available dataset. In order to repeat training on the same model parameters 100 times, i.e. 100 epochs instead of 1 epoch we need 80 * 100 = 8000 steps. So if we set 10 000 steps we ask for 125 epochs since 2000 steps is 25 epochs.
Training
estimator.train(
() => trainData,
tf.learn.StopCriteria(maxSteps = Some(10000))
)Finally we are starting the training loop. We pass the same trainData as we used
for metric evaluation. However, we could use different datasets for training and metric evaluations. We override maxSteps with 10 000. As we have only 10k rows in CSV file, we do not need initial 100 000 steps for training. TensorFlow
Once we run train method, we can see the following output in console:
.....
2021-02-12 19:07:15.308 [run-main-9] INFO Learn / Hooks / Evaluation - Step 10000 Evaluator:
2021-02-12 19:07:15.308 [run-main-9] INFO Learn / Hooks / Evaluation - ╔═══════╤════════════╗
2021-02-12 19:07:15.308 [run-main-9] INFO Learn / Hooks / Evaluation - ║ │ Accuracy ║
2021-02-12 19:07:15.308 [run-main-9] INFO Learn / Hooks / Evaluation - ╟───────┼────────────╢
2021-02-12 19:07:15.369 [run-main-9] INFO Learn / Hooks / Evaluation - ║ Train │ 0,8494 ║
2021-02-12 19:07:15.386 [run-main-9] INFO Learn / Hooks / Evaluation - ║ Test │ 0,8367 ║
2021-02-12 19:07:15.391 [run-main-9] INFO Learn / Hooks / Evaluation - ╚═══════╧════════════╝there will be 11 logging statements for intermediate accuracy value, so I copied only the last summary.
train method returns Unit, so it mutates state of the estimator, so that you can use
it further for model inference.
Single test
val example = TextLoader(
"n/a,n/a,n/a,600,France,Male,40,3,60000,2,1,1,50000,n/a"
).cols[String](3, -1)
val testExample = Tensor(dataTransformer(example).map(Tensor(_)).toSeq)
.reshape(Shape(-1, features))
val prediction = estimator.infer(() => testExample)
println(s"Customer exited ? ${prediction.scalar > 0.5f}")We use dataTransformer function one more time for converting raw single data record into
numeric format that our model can understand and return a target value for it:
Customer exited ? falsefalse is expected value for that simple example.
Batch test
We can also submit data batch to infer a target value for each record.
println(s"Train accuracy = ${accuracy(xTrain, yTrain)}")
println(s"Test accuracy = ${accuracy(xTest, yTest)}")We are going to calculate the accuracy metric manually based on known labels for train and test datasets:
def accuracy(input: Tensor[Float], labels: Tensor[Float]): Float = {
val predictions = estimator.infer(() => input.toFloat).toArray
val correct = predictions
.map(v => if (v > 0.5f) 1f else 0f)
.zip(labels.toFloat.toArray)
.foldLeft(0f) { case (acc, (yHat, y)) => if (yHat == y) acc + 1 else acc }
correct / predictions.length
} Train accuracy = 0.867875
Test accuracy = 0.8605Although we used again the same data for checking accuracy, however one can take new / unseen data to check the accuracy on just trained or loaded from checkpoint estimator.
Tensorboard
Tensorboard is an additional tool from TensorFlow main framework. It can be installed via pip tool:
pip install tensorboardWe enable Tensorboard as part of Estimator configuration. Every time we run training cycle for an estimator with Tensorboard configured, we get the following console message:
sbt:tensorflow-scala-example> run
[info] running MultipleLR
2021-02-12 21:09:04.933 [run-main-c] INFO Learn / Hooks / TensorBoard - Launching TensorBoard in 'localhost:6006' for log directory '..../tensorflow-ann/temp/ann'TensorFlow starts a web-app at localhost on port 6006 and using data from the the log directory that we configured at estimator level.
Log directory accumulates TensorFlow logs between training cycles, so that if we run training cycle again and again we can see that estimator variables (graph state) is restored from that logging folder. Eventually, our model loss and accuracy metric values are going to be stable, i.e. not improving anymore.
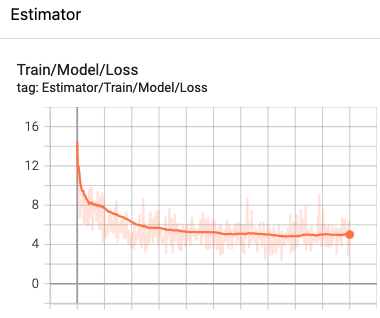
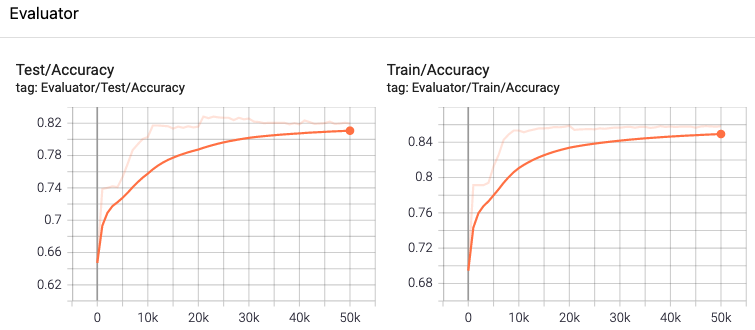
Summary
TensorFlow Scala is a fantastic library that mimics most of TensorFlow core library and Python API.
Although current library is missing some documentations, one can always use official TensorFlow documentation web-site to get an idea of the Scala API.
Implemented ANN in TensorFlow Scala shows that one can use Scala to train Deep Learning models easily. Training program in Scala are going to be quite declarative and statically type-checked which eliminates lots of mistakes. Library API also allows to extend most of the abstractions, which is very important for real life use cases.
Source Code
Full source code as SBT project can be found here: