Machine Learning with Flink
If you want to add Machine Learning capabilities into your Flink job then this article is for you. As Flink runs on Java Virtual Machine, we are constrained by the tools which JVM supports. However, there are still plenty of options to choose in order to perform model training and inference as part of a Flink job.
Supervised Machine Learning
Before we dive into Flink specifics to apply Machine Learning, let's first define key points of Supervised Machine Learning.
In Supervised Machine Learning we feed data into the algorithm containing the right answers. Then we check whether the algorithm can eventually learn those answers on its own by feeding new or test data. That means we supervise the algorithm until we reach desired model performance in terms of accuracy, error rate and other metrics.
Training phase is usually done on a batch data iteratively. In other words, our training data set is already prepared and stored on disk in one or multiple files. Flink can read all of those files in streaming or batch mode. However, it does not make sense much to use streaming mode, because streaming job will start to poll for additional files on disk and won't terminate on its own, unless special Flink configuration is set such like "streaming - bounded" mode to facilitate natural job termination. The same approach would be applicable for a message queue as a training data source, where data set would be a sequence of messages, which we need to read all to eventually train the model.
There is another approach when ML model is trained on so called "online data", i.e. it reads real-time data continuously and also updates model weights as part of the training. This process ideally never ends, because it is part of the production application. That means we train the model and use it to score real data in parallel.
Most common approach in Supervised Machine Learning these days is training on offline data in batch mode. In this blog post we will focus on this approach specifically. We will use Flink batch jobs to read prepared data and run training cycle to get the trained model. Once trained model is ready, it will be stored on disk and then can be loaded by another job to do model inference as part of the application logic.
Data Streaming and ML
Let's quickly define basic definitions for training and inference to build up further concepts on top of them:
Model Training:
- It is iterative process which runs on the finite dataset
- Training is usually done on schedule (once per hour or day or week, i.e. depends on data updates)
- If training is done on online data, then the training loop repeats infinitely and updates internal model weights on every record or window / mini-batch
Model Inference:
- It is a call of a math function like "y = model(x)", where
xis feature vector andyis prediction vector.- In streaming mode: a call on every input record
- In batch mode: a call for entire mini-batch at once
Both definitions above are true for Supervised and Unsupervised Machine Learning.
Model re-training and updates
Once model is trained and stored on disk, it may become outdated very soon. Of course, it depends whether our environment may get new data to learn something new from it. In many business domains, data does not change fast, so we can train a model and use it for many days or months without re-training it again.
In order to update a model in the running Flink job, we have several options:
For cases when Flink job calls a model inside JavaVM or PythonVM:
- Restart Flink job loading newer model (for cases when ML model is loaded on job startup).
- Refresh ML model version in memory periodically or on some event. This option minimizes Flink job downtime.
For cases when Flink calls a model using remote procedure call (RPC), i.e. over the network, the Flink job restart is not needed, but that external service may lead to the Flink job outage or temporary failures, when the external service is restarted.
In order to mitigate external service outage or achieve zero-time outage for the Flink side, a DevOps team in charge can apply different techniques such as:
- Blue-Green deployments for the external service to serve the latest and previous model version in the same time
- Additionally, configure a network load balancer to automatically switch to a new model version once it is up and running.
ML Libraries for Flink
As a Flink developer you might have a question - can we easily do ML training in Flink? Can it be also done with the popular ML libraries like Scikit-Learn, Pytorch, Tensorflow, etc.?
The answer to the first question is yes, we can do ML tasks in Flink. As for the second question we can also answer as yes, however it does not make sense to run training of Scikit-Learn based model in Flink, if it is not integrated with Flink runtime and its job operators. That said, we can't easily leverage Flink distributed runtime to run training process efficiently. Ideally we want to use all Flink cluster task managers. Certain tasks in ML training can still benefit from Flink runtime. For example, training with cross-validation (different training and test data set splits). where every data split would be run on its own Flink task if we submit all splits concurrently. If no cross validation is used, then we will be running training on a single task within a single task manager. Thus, this neglects the whole idea to use Flink runtime for training as it will be underutilized and will bring a lot of extra work for a developer without giving benefits. That said, the idea to use Flink without low-level integration of Flink tasks and operators with specific external library does not worth it. It would be the same effect as we training ML model without Flink runtime, but directly on some VMs running ML programs sequentially or in parallel for different data set splits.
The good news is Flink has its own ML module called Flink ML. Flink ML supports training and model inference. It fully utilizes Flink tasks to distribute training process within a Flink cluster. Of course, Flink ML module limits us by only those ML algorithms, which it supports at the moment. As of today, it is quite rich list of supported ML algorithms including typical data preparation algorithms, for example data normalization.
External Libraries
When it comes to other libraries, which are coming from Python or C world, we can only use them in Flink to do a model inference.
In order to load a model produced by external library, we either use available JVM SDK of that library or we can also use PyFlink and load any Python-based model.
If our ML library has C/C++ interface, then we can also use JVM language wrappers for those libraries, for example libtorch has Scala wrapper storch.
In this case native library will be used via Java Native Interface.
Ways to do ML in Flink
Let's look at the table below with all options we have to apply Machine Learning in Flink:
| Library Name / Approach | Native Training Support | Inference Support | Remark |
|---|---|---|---|
| Flink ML | x | x | Easy to use. Most common algorithms are supported |
| Deep Learning on Flink: Tensorflow, Pytorch integration | x | x | Allows to train inside a Flink cluster. Caveat: this community project requires dependency upgrades |
| JVM runtimes for model formats like PMML, ONNX (ex: onnx-scala, flink-jpmml) | x | Fast and generic way | |
| Python libraries via Flink Table API (UDF) | x | Any Python library can be used, but it can be slow due to the PythonVM itself and data exchange | |
| Scala wrappers for C/C++ libraries (libtorch, etc.) | x | Today is mainly limited to Pytorch or Tensorflow |
Empty table cell above means we train a model outside of Flink, e.g. in any other programming language.
Generic ML Workflow with Flink
Below workflows use Flink at the Inference phase only (right side). In the most common situation, development teams establish their training pipelines outside of Flink using external libraries.
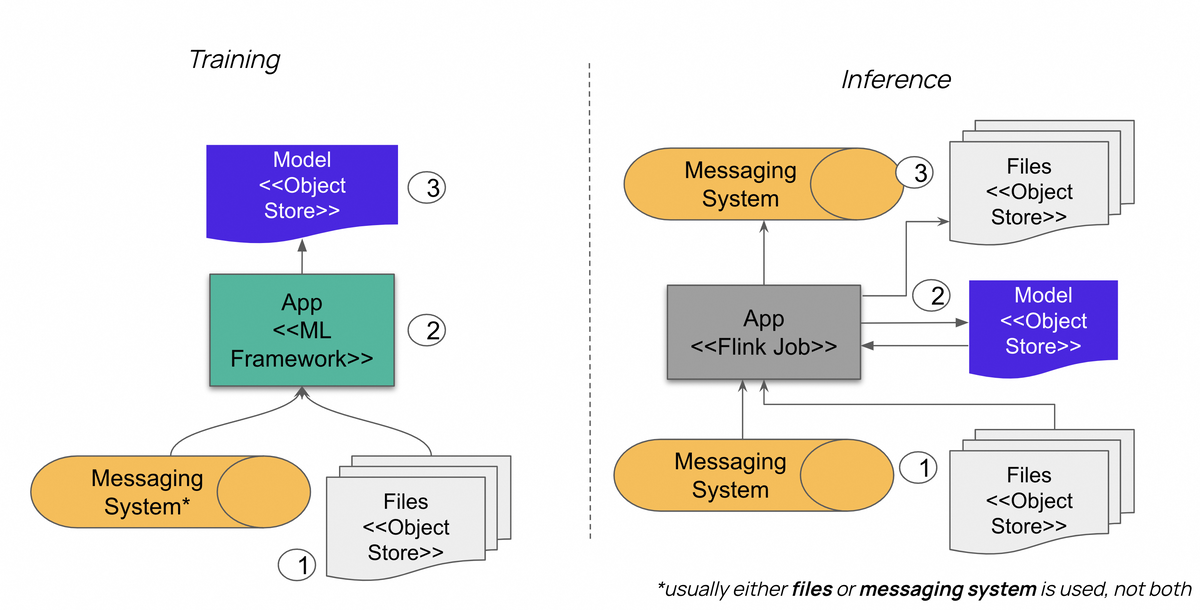
Figure 1. Training and Inference workflows with and w/o Flink
Training
In the Training phase we run an application, which (1) reads data from disk, object storage or consumes a set of data from messaging system like Apache Kafka. This application can be a Flink job which uses FlinkML module or some other ML Framework via PyFlink. The ML application can (2) consume data in mini-batches or read it record by record. While running a training loop, the application updates current model weights in memory and (3) stores them periodically to a persistent storage (file system, object storage like AWS S3). Training loop usually runs dozen of times until it reaches certain thresholds of the training metrics and some other control conditions.
Inference
In the Inference phase we run Flink Job which may or may not share some code with the training job. The main point is that the inference Flink job loads already trained model and uses the same ML framework to call the model. At the beginning, inference job reads (1) data similarly to the training job, but this time it reads unseen data to (2) apply ML model and stores the results to the sink system. Usually the results are stored on every record to (3) messaging system or some persistent storage.
Flink ML Module
In this blog we uncover Flink ML module and look at its applications. In the next blog posts we look at further ways for ML tasks in Flink such as ONNX, PyFlink and C/C++ wrappers.
Flink ML module supports training and inference for the most popular supervised and unsupervised ML algorithms. This module uses Flink job primitives to build a distributed graph of operators to perform model training or inference. ML job runs in distributed mode utilizing all available Flink task managers in the cluster.
Flink ML algorithms are implemented as operators. You can see them in the Flink UI when opening job graph visualization. Flink's Table API is a basis for Flink ML. It uses Table type to represent input and output data.
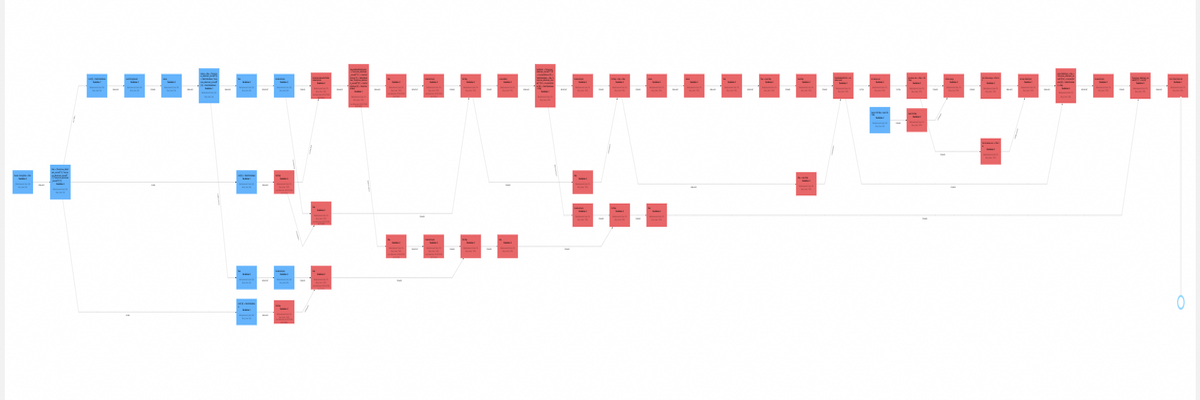
Figure 2. Flink Job graph of LogisticRegression model training and validation.
Above figure shows a large Flink Job graph from the Flink UI, which is built by Flink Table API and Flink ML to run data preparation and Logistic Regression training process. We will see how to train such a model in details further.
Algorithms supported by the FlinkML
| Task | Algorithms |
|---|---|
| Classification | K-Nearest Neighbor, Linear SVC, Logistic Regression, Naive Bayes |
| Clustering | AgglomerativeClustering, Kmeans |
| Recommendation | Swing |
| Regression | Linear Regression |
| Statistics | ChiSqTest |
| Evaluation | Binary Classification, Evaluator |
| Feature Engineering | Normalizer, Scalers, Binarizer and many others |
| Stats | ChiSqTest |
Example: Logistic Regression
Let's implement an ML application in Flink for Customer Churn Analysis by using Flink ML's Logistic Regression algorithm. This use case is quite typical task for enterprises which want to find unhappy customers and offer better conditions to retain them.
The goal of our model is to predict whether a customer may leave a bank or not.
As clients data, we use syntetic data set prepared and stored in CSV file format in local filesystem. Clients data has all required columns to train the ML model.
Data Preparation
Below is the data sample in CSV format which we will use by the training job:
RowNumber,CustomerId,Surname,CreditScore,Geography,Gender,Age,Tenure,Balance,NumOfProducts,HasCrCard,IsActiveMember,EstimatedSalary,Exited
1,15634602,Hargrave,619,France,Female,42,2,0,1,1,1,101348.88,1
2,15647311,Hill,608,Spain,Female,41,1,83807.86,1,0,1,112542.58,0
3,15619304,Onio,502,France,Female,42,8,159660.8,3,1,0,113931.57,1
4,15701354,Boni,699,France,Female,39,1,0,2,0,0,93826.63,0
For our application we skip irrelevant columns such as RowNumber, CustomerId, Surname and use all other columns (features) of this dataset:
CreditScore,
Geography,
Gender,
Age,
Tenure,
Balance,
NumOfProducts,
HasCrCard,
IsActiveMember,
EstimatedSalary
Column Exited is our target label to predict. It contains binary value such as 0 or 1, which encodes the following logic:
- 0 - client won't exit the bank;
- 1 - client will exit the bank
Before we feed the selected data columns into the any ML algorithm, we need to transform this data into numerical format. At this point we start to name data columns as features. Categorical features should be encoded with one-hot encoder, numerical features also known as continues features should be normalized. Specific data encoding and normalization is needed to achieve the highest model accuracy and the lowest error rate during the training or simply saying this helps to achieve the best learning performance in terms quality.
To learn more on feature engineering topic I advise you to read special literature on that. In this blog post we focus on Flink ML module itself.
Load CSV as Flink Table
First we use Flink DataStream API to load tabular CSV data from file and parse it into the Row type.
val source = FileSource
.forRecordStreamFormat(
TextLineInputFormat(),
filePath
)
.build()
val csvStream = env
.fromSource(source, WatermarkStrategy.noWatermarks(), "trainingData")
.filter(l => !l.startsWith("#")) // removing comments
.map(l =>
// from CreditScore to Exited
val row = l.split(",").slice(3, 14)
Row.of(
row(0).toDouble,
row(1),
row(2),
row(3).toDouble,
row(4).toDouble,
row(5).toDouble,
row(6).toDouble,
row(7).toDouble,
row(8).toDouble,
row(9).toDouble,
row(10).toDouble
)
)
val trainData = tEnv.fromDataStream(csvStream)
trainData is the input data to our data preprocessing step.
Prepare ML Features
// 1 - index Geography and Gender
val indexer = StringIndexer()
.setStringOrderType(StringIndexerParams.ALPHABET_ASC_ORDER)
.setInputCols("GeographyStr", "GenderStr")
.setOutputCols("GeographyInd", "GenderInd")
StringIndexer turns string (categorical) columns into integer-indexed columns.
For each Country and for both Genders we will have an integer value from 0 to N, where N is a number of unique values in the column.
In case of country column, N is 3 as we have 3 countries in the data set.
// 2 - OneHot Encode Geography and Gender
val geographyEncoder =
OneHotEncoder()
.setInputCols("GeographyInd", "GenderInd")
.setOutputCols("Geography", "Gender")
.setDropLast(false)
OneHotEncoder creates an additional column per each unique category in the original column.
Output columns "Geography" will be divided into 3 columns and "Gender" into 2 columns.
That means we get 5 columns instead of these 2 original columns in the resulting table.
Other feature columns so far stay unchanged.
Merge to a Vector column
Before we normalize continues features, we need to merge individual columns into a single column. That means the resulting column will look like:
row0: .. |DenseVector(42,2,0,1,1,1,101348.88)| ..
row1: .. |DenseVector(41,1,83807.86,1,0,1,112542.58)| ..
... etc.
// 3 - Merge to Vector
val continuesCols = List(
"CreditScore",
"Age",
"Tenure",
"Balance",
"NumOfProducts",
"EstimatedSalary"
)
val assembler = VectorAssembler()
.setInputCols(continuesCols*)
.setOutputCol("continues_features")
.setInputSizes(List.fill(continuesCols.length)(1).map(Integer.valueOf)*)
By merging these columns into a single column, we prepare training data for the final stage of the training pipeline, which is LogisticRegression model.
Its input format requires to fit a single column with all features per row.
Normalize Numbers and Merge Columns
// 4 - Normalise numbers
val standardScaler = StandardScaler()
.setWithMean(true)
.setInputCol("continues_features")
.setOutputCol("continues_features_s")
// 5 - merge columns to features col
val categoricalCols = List("Geography", "Gender", "HasCrCard", "IsActiveMember")
val finalCols = categoricalCols :+ "continues_features_s"
// Geography is 3 countries, Gender is 2 + other 8 features
val encodedFeatures = List(3, 2)
val vectorSizes = encodedFeatures ++
List.fill(categoricalCols.length - encodedFeatures.length)(1) :+ continuesCols.length
val finalAssembler = VectorAssembler()
.setInputCols(finalCols*)
.setOutputCol(featuresCol)
.setInputSizes(vectorSizes.map(Integer.valueOf)*)
StandardScalertransforms a column values using column mean and standard deviation values.VectorAssemblermerges all input columns into one single column, which we name asfeatures.
The resulting table format will have two columns:
features: DensVector | label: Double
Train the Model

Figure 3. Model riding the train
Now we combine all stages and train the model:
val lr = LogisticRegression()
.setLearningRate(0.002d)
.setLabelCol(exitedLabel)
.setReg(0.1)
.setElasticNet(0.5)
.setMaxIter(100)
.setTol(0.01d)
.setGlobalBatchSize(64)
val stages = (List[Stage[?]](
indexer,
geographyEncoder,
assembler,
standardScaler,
finalAssembler,
lr
)).asJava
val pipeline = Pipeline(stages)
val testSetSize = 2000
val totalSetSize = 10000
val trainSetSize = totalSetSize - testSetSize
val trainSet = trainData.limit(trainSetSize)
val testSet = trainData.limit(trainSetSize, testSetSize)
val pipelineModel = pipeline.fit(trainSet)
Our training pipeline consists of data preparation stages and LogisticRegression evaluator.
LogisticRegression as the last stage is going to keep and train model weights.
Method fit executes the training loop. Input data goes through all the stages sequentially.
The pipelineModel variable is a trained model which we use further to assess its quality by calculating several metrics.
Validate the Model
val validateResult = pipelineModel.transform(testSet)(0)
val resQuery =
s"""|select
|$featuresCol,
|$exitedLabel as $labelCol,
|$predictionCol,
|rawPrediction
|from $validateResult""".stripMargin
val iter = tEnv.sqlQuery(resQuery).execute.collect
val firstRow = iter.next
val colNames = firstRow.getFieldNames(true).asScala.toList.mkString(", ")
val correctCnt = (List(firstRow).toIterable ++ iter.asScala).foldLeft(0) {
(acc, row) =>
println(row)
val label = row.getFieldAs[Double](labelCol)
val prediction = row.getFieldAs[Double](predictionCol)
if label == prediction then acc + 1 else acc
}
println(colNames)
println(
s"correct labels count: $correctCnt, accuracy: ${correctCnt / testSetSize.toDouble}"
)
In the result, above calculation will print all the validate set rows with their predictions and final accuracy metric value:
.... < a lot of rows here>
+I[[1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.6078536710583327, -0.2776327360064674, 0.6985644677637127, -1.2297164068458775, -0.9064018047377373, -1.0106520912894439], 1.0, 0.0, [0.5157926901008845, 0.48420730989911553]]
features, label, prediction, rawPrediction
correct labels count: 1619, accuracy: 0.8095
Among 2000 validate set rows we got 1619 correctly labeled, which is 81% correctness of the trained model.
One more useful evaluation of the model performance is to use Flink ML BinaryClassificationEvaluator:
val evaluator = BinaryClassificationEvaluator()
.setLabelCol(exitedLabel)
.setMetricsNames(
ClassifierMetric.AREA_UNDER_PR,
ClassifierMetric.KS,
ClassifierMetric.AREA_UNDER_ROC,
ClassifierMetric.AREA_UNDER_LORENZ
)
val outputTable = evaluator.transform(validateResult)(0)
val evaluationResult = outputTable.execute.collect.next
println(
s"Area under the precision-recall curve: ${
evaluationResult.getField(ClassifierMetric.AREA_UNDER_PR)}"
)
println(
s"Area under the receiver operating characteristic curve: ${
evaluationResult.getField(ClassifierMetric.AREA_UNDER_ROC)}"
)
println(
s"Kolmogorov-Smirnov value: ${evaluationResult.getField(ClassifierMetric.KS)}"
)
println(
s"Area under Lorenz curve: ${
evaluationResult.getField(ClassifierMetric.AREA_UNDER_LORENZ)}"
)
We get the following values:
Area under the precision-recall curve: 0.3690456181301246
Area under the receiver operating characteristic curve: 0.6990527666047854
Kolmogorov-Smirnov value: 0.2932136963696369
Area under Lorenz curve: 0.6608346354166658
We are not going to try to improve current metrics and overall model performance. That would be a subject for another blog post.
Save and Load Model
If we need to save learned model weights and then later load them again, Flink ML has special methods for that:
Save Model data:
pipelineModel.save("target/customer-churn-model/pipeline")
env.execute("Save PipelineModel")
Do not forget to call execute method to trigger model saving at the specified path.
In the result we will get the following metadata and data on disk:
target/customer-churn-model/pipeline/
├── metadata
└── stages
├── 0
│ ├── data
│ │ └── part-a64dc5f8-aa9f-4926-b3c4-741046d6191b-0
│ └── metadata
├── 1
│ ├── data
│ │ ├── part-820018d4-6bf6-4494-8de1-88e26b94054c-0
│ │ └── part-8471e23f-af15-438e-9c10-a32e34ac9a64-0
│ └── metadata
├── 2
│ └── metadata
├── 3
│ ├── data
│ │ └── part-4008d3e0-259e-41a7-923f-12522d6a8950-0
│ └── metadata
├── 4
│ └── metadata
└── 5
├── data
│ └── part-aac4d931-8dea-4ee3-8610-884dc158e31d-0
└── metadata
Load Model data:
val model = PipelineModel.load(tEnv, "target/customer-churn-model/pipeline")
val validateResult = model.transform(validateSet)(0)
...
Flink ML Summary
In result we were able to create a Flink job which can learn and train ML model for Customer Churn Analysis using LogisticResgression algorithm.
As part of the learning process, we were able to prepare data in the proper format using Flink ML encoders and scalers utilities.
In case we want to use the trained model further, we can store and load its state in the same or in a completely new Flink job.
This allows us to train ML models in Flink on a specific environment and use them later in production.
Flink ML also allows to extend it with own ML algorithm using FlinkML API.